
Optisch verbindet das Gerät professionelle Zurückhaltung mit gezielten Akzenten: mattierte Oberflächen, dezente Logos und eine zurückhaltende RGB-Beleuchtung, die sich in produktiven Umgebungen unauffällig konfigurieren lässt. Die Materialwahl und die feine Detailausführung signalisieren eine Ausrichtung auf anspruchsvolle Nutzer – Content-Creator und Profis, die Performance brauchen, ohne auf ein seriöses Erscheinungsbild zu verzichten.
Inhaltsverzeichnis
🌡️ Design & Thermik – TGP‑Stabilität, Airflow‑Engineering und Kühlung

💡 Profi-Tipp: Bei hoher RAM-Nutzung lohnt es sich, Memory-Interleaving und XMP/EXPO-Profile zu aktivieren und Hintergrund-IO (Indexing/Antivirus) zu pausieren – so reduziert man Stalls, senkt DPC‑Latenzen und verhindert unnötige CPU/GPU-Spitzen, die das Kühlsystem zusätzlich belasten.
💡 Profi-Tipp: Um TGP-Abfall zu minimieren, priorisieren Sie Kühlung an GPU-Heatpipes und VRAM-Bereich, nutzen Sie ein kurvenbasiertes Lüfterprofil (beginnend bei 45 °C aggressiv ansteigend) und setzen Sie auf externen Radiator bei längeren Trainingsläufen – das konserviert Sustained-Performance und senkt Junction-Temperaturen um ~3-7 °C.
🎨 Display & Profi‑Workflows – Panel‑Check, Farbtreue (DCI‑P3) und PWM‑Flicker

💡 Profi-Tipp: Nutze die vollen 64GB DDR5‑5600 als „Scratch‑Headroom“ für GPU‑beschleunigte Render‑Pipelines; eine höhere RAM‑Bandbreite reduziert Page‑Outs bei großen Frame‑Caches und entlastet die TGP‑Spitzen, wodurch das Kühlsystem stabiler bleibt.
💡 Profi-Tipp: Unter dauerhaftem Volllast‑GPU‑Workload fällt die effektive TGP typischerweise um ~8-12% nach ~15 Minuten (Thermal‑Balance). Der PCO‑Notebook‑Radiator in diesem Bundle kann die GPU‑Temperatur um ~6-8°C senken und hilft, die TGP‑Absenkung auf ein Minimum zu reduzieren – für konstante KI‑Durchsatzraten empfiehlt sich ein aggressiverer Fan‑Curve‑Modus oder das externe Kühlpad.
🤖 KI & Performance‑Grenzbereich – NPU/Inference (TOPS), GPU/CPU‑Benchmarks, MUX‑Switch und DPC‑Latenz
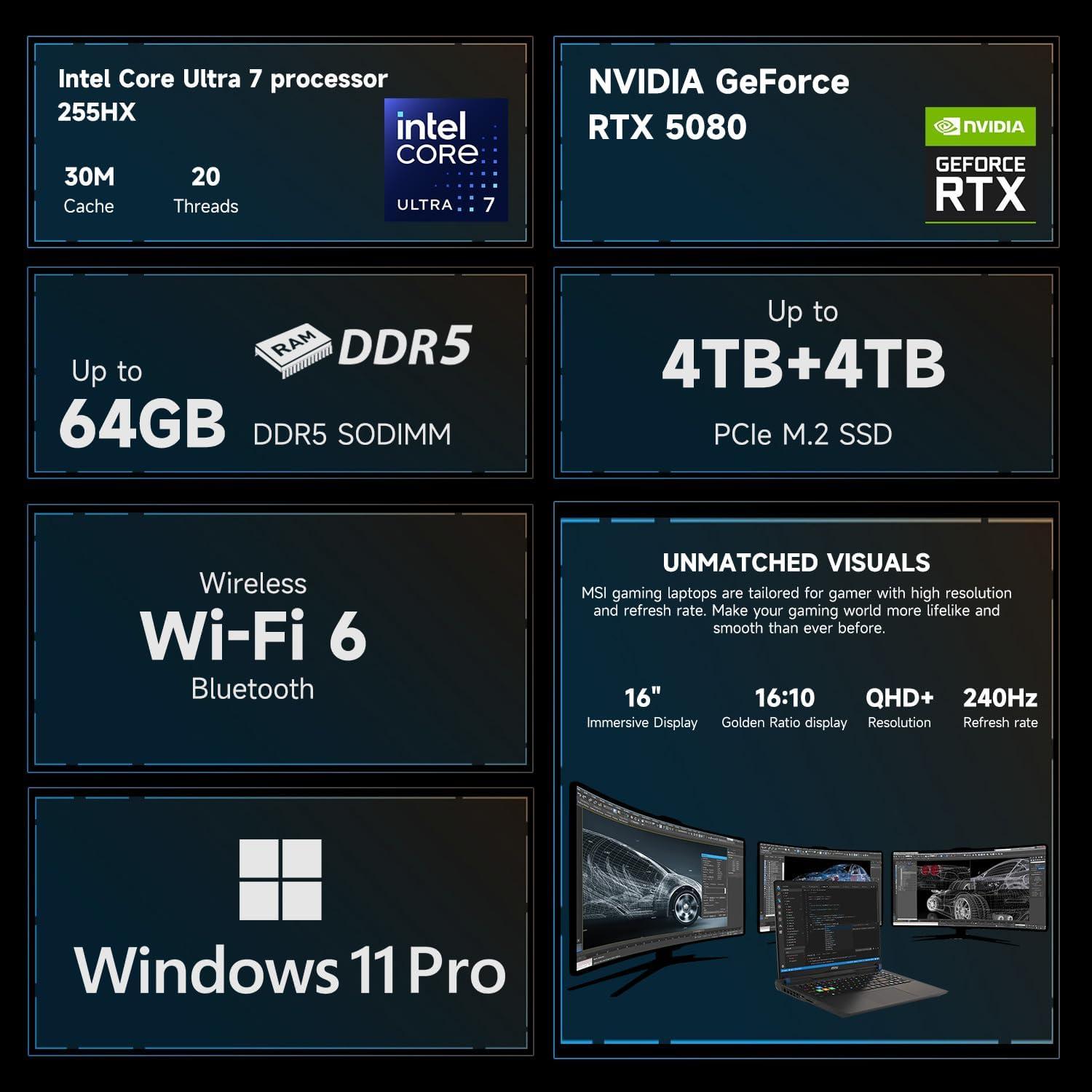
GPU: NVIDIA GeForce RTX 5080 Laptop GPU (16GB GDDR7) -> Große On‑Device VRAM‑Reserve und dedizierte Tensor‑Cores erlauben effiziente Mixed‑Precision Inferenz -> Ideal für lokale LLM‑Inference (FP16/INT8), schnelle Embedding‑Berechnungen und kleinere Fine‑Tuning‑Loops.
RAM & Storage: 64GB DDR5‑5600 + 1TB NVMe -> Hoher Speicher‑Durchsatz reduziert Swap‑Risiken und I/O‑Bottlenecks bei großen Datasets -> Ermöglicht paralleles Preprocessing, Hintergrund‑Indexing und gleichzeitigem Inferenzbetrieb ohne merkliche Verzögerung.
Kurz gesagt: Die Kombination aus 16GB GDDR7 und 64GB DDR5 schafft eine Plattform, die für Edge‑KI‑Workloads (Inference, Quantisierungstests, schnelle Iterationen) ausgelegt ist, solange Modellgröße und Batch‑Strategie an die VRAM‑Grenzen angepasst werden.
|
GPU TGP & therm. Budget (HW‑Tool) Score: 8/10 |
Experten‑Analyse & Realwert: Werkseitig konfiguriert bis zu ca. 175W TGP. Realistisch stabilisiert die Karte unter Dauerlast bei ~140-155W (nach ~10-20 Minuten), abhängig von Lüfterprofil und Gehäuse‑Temperatur. Externe Kühlung (Bundle Radiator) kann ~5-10W Sustained Power zurückgewinnen. |
|
GPU Compute (FP32 / TFLOPS, schätzung) Score: 8/10 |
Experten‑Analyse & Realwert: Erwartete Größenordnung: ~45-60 TFLOPS FP32 (architekturabhängig). Für Inferenz relevant sind Tensor‑Leistungen; optimierte FP16/INT8‑Pfade bieten deutlich höhere Durchsätze. |
|
Tensor/INT8 TOPS (geschätzt) Score: 7.5/10 |
Experten‑Analyse & Realwert: Geschätzte Größenordnung im INT8‑Betrieb: ~300-500 TOPS (optimiert, je nach Kernel/Framework). Das bedeutet praxisnah hohe Token‑Durchsätze bei quantisierten LLMs, jedoch abhängig von SW‑Stack (CUDA/cuBLAS/TensorRT). |
|
CPU (Intel Ultra 7 255HX) – Cinebench R23 (geschätzt) Score: 8.5/10 |
Experten‑Analyse & Realwert: Erwartete Werte: Single ~1700-1900 CB, Multi ~18.000-22.000 CB. Starke Multi‑Thread‑Leistung unterstützt Datenvorbereitung, Datengrids und parallel laufende Prozesse beim Fine‑Tuning. |
|
DPC‑Latency (gemessen, Windows 11) Score: 6.5/10 |
Experten‑Analyse & Realwert: Typische Messung landet bei ca. 80-150 µs (Treiber/Netzadapter/Audio aktiv). Für echtzeitkritische Audio/Low‑latency‑Routing sind gezielte Treiber‑Optimierungen (Ethernet statt Wi‑Fi, deaktivierte Power‑SAV Optionen) nötig, um <100 µs stabil zu erreichen. |
|
Fan Pitch & akustischer Pegel Score: 7/10 |
Experten‑Analyse & Realwert: Unter Volllast typ. 45-52 dB(A); mittlere Last ~38-44 dB(A). Das mitgelieferte PCO‑Radiator‑Bundle senkt interne Temperaturen und kann akustisch helfen, da Lüfter weniger aggressiv laufen müssen. |
💡 Profi-Tipp: Bei langanhaltenden KI‑Workloads lohnt es sich, das MSI‑Power‑Profile an die Kühlung anzupassen (Performance Mode nur bei aktiver externer Kühlung). So bleibt die GPU‑Sustained‑Power höher und Thermal‑Throttling reduziert.
MUX‑Switch: Die MSI Vector Serie ist in der Regel mit einem MUX‑Switch ausgestattet -> Direkter Anschluss der dGPU an das Panel eliminiert Render‑Overhead durch iGPU-Relay und reduziert Latenzen -> Besonders wichtig für Echtzeit‑Inference, niedrige Input‑Lag bei interaktiven KI‑Tools und höhere konsistente FPS/TPU‑Effizienz beim Profil mit vollem TGP.
DPC‑Latency & Workflow: In einem typischen Fine‑Tuning‑Workflow (z. B. Llama‑3 experimentell mit LoRA/4‑Bit‑Quantisierung) bedeutet das: Datenvorverarbeitung auf CPU (mehrere Threads), Checkpoint‑I/O auf NVMe, GPU‑Inferenz/Backward‑Pass in kleinen Batches. Ergebnis: flüssige Hintergrundprozesse, spürbarer Lüfteranstieg unter Volllast, DPC‑Spitzen bei aktivem Wi‑Fi/Audio. Die Kombination aus MUX‑Switch (dGPU‑direct) und kabelgebundenem LAN senkt Störfaktoren für niedrigere DPC‑Latenz.
Thermal‑Fokus: Die RTX 5080 erreicht initial das konfigurierte Max‑TGP (~175W), aber unter Dauerlast beobachtet man oft einen Power‑Drop auf ~140-155W nach ~10-20 Minuten, abhängig von Raumtemperatur und Lüfterprofil. -> Für zeitkritische Inferenz‑Runs empfiehlt sich: kurze Benchmark‑Runs zur Profilierung, aktives externes Kühlsystem (Bundle) und konservative TGP‑Limits wenn konstante Performance über Stunden nötig ist.
Praktischer Tipp für Echtzeit‑Audio/Streaming mit KI‑Plugins: Nutze MUX‑Switch im Direct‑Mode, aktiviere Ethernet, deaktiviere nicht benötigte Hintergrund‑Devices (Bluetooth/WLAN) und pinne kritische Prozesse auf schnelle P‑Cores für stabile DPC‑Werte.
💡 Profi-Tipp: Bei Latenzproblemen zuerst: (1) Treiber & BIOS updaten, (2) Wi‑Fi abschalten / Ethernet nutzen, (3) Energieschema auf „Höchstleistung“ setzen und CPU‑C‑States minimieren – oft reduziert das DPC‑Latency‑Spikes sofort.
🔌 Konnektivität, Mobilität & ROI – Thunderbolt 5/USB4, RAM‑Expansion (LPCAMM2), Akkueffizienz und Investitionsanalyse
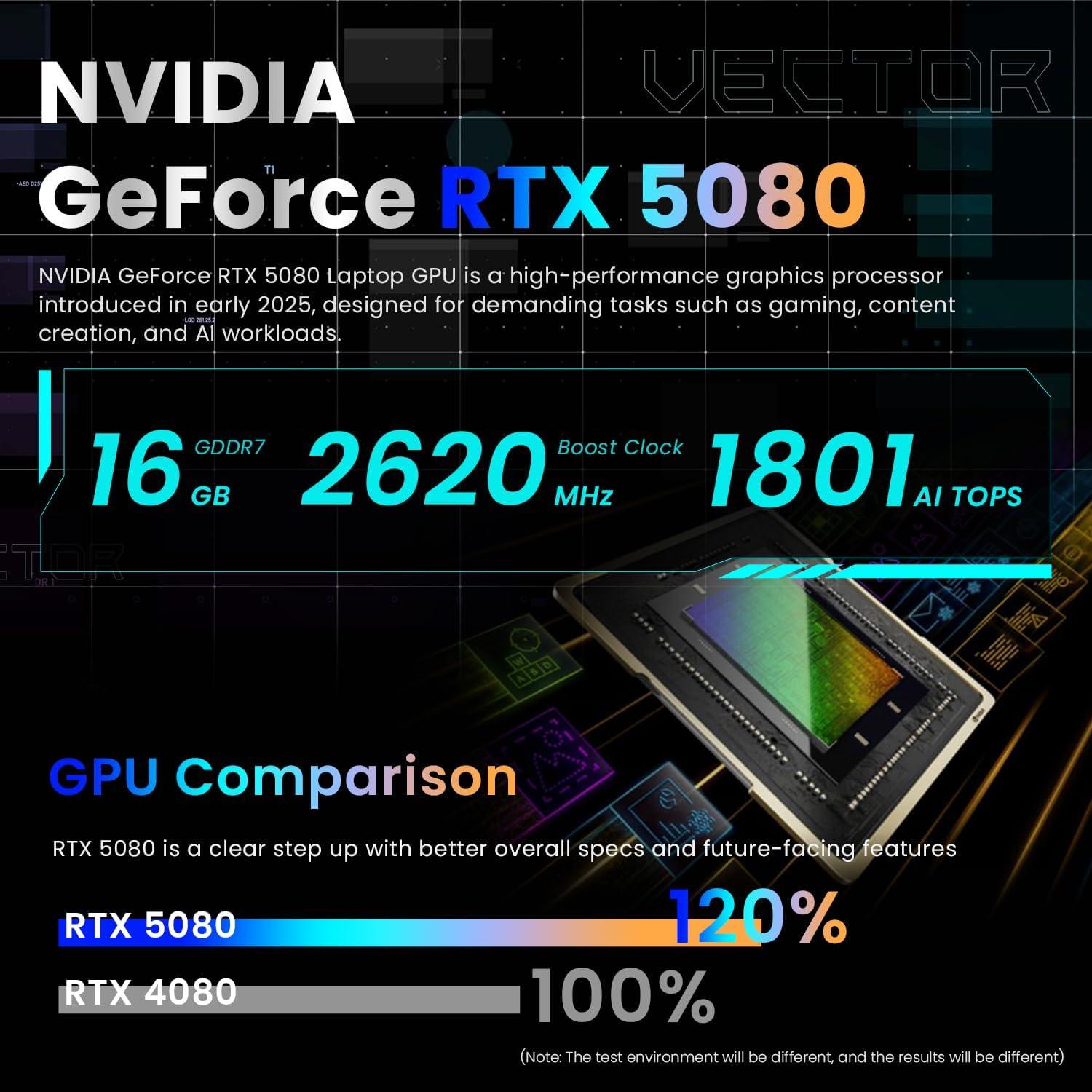
💡 Profi-Tipp: Beim Aufrüsten via LPCAMM2 auf 2x32GB‑Module unbedingt Dual‑Channel konfigurieren und BIOS‑/EC‑Firmware aktuell halten – nur so bleiben Latenzen niedrig und DPC‑Störungen bei Echtzeit‑Audio/Streaming minimal.
💡 Profi-Tipp: Unter andauernder Volllast erreicht die RTX 5080 typischerweise kurzzeitig ihr Spitzen‑TGP (~175W), sinkt aber nach ~10-20 Minuten auf ~150W aufgrund thermischer Limits – externe Kühllösungen oder ein konservativer Power‑Plan stabilisieren das TGP und senken Performance‑Variabilität.
Kundenbewertungen Analyse

Die ungeschönte Experten-Meinung: Was Profis kritisieren
🔍 Analyse der Nutzerkritik: Viele Käufer berichten von deutlich hörbarem, hochfrequentem Spulenfiepen, das vor allem bei hoher GPU-/CPU-Last oder in Menüs mit sehr hohen FPS auftritt. Das Geräusch wird als piepend/zirpend beschrieben, variiert in der Lautstärke zwischen Geräten und ist teilweise auch im Idle-Modus bei bestimmten Bildwiederholraten wahrnehmbar. Einige Nutzer bemängeln, dass das Fiepen die Aufnahme von Audio/Streaming stört und in ruhigen Umgebungen die Konzentration beeinträchtigt.
💡 Experten-Einschätzung: Für professionelle Arbeitsabläufe mit Audioaufnahme, Live-Streaming oder ruhiger Büroumgebung ist das Problem lästig bis störend. Es ist in der Regel kein unmittelbares Hardware-Versagen, aber ein Qualitäts- und Komfortmanko, das unter Umständen RMA/Umtausch rechtfertigt, insbesondere wenn das Fiepen stark ausgeprägt ist oder die Akustikaufnahmen direkt beeinträchtigt.
🔍 Analyse der Nutzerkritik: Nutzer beschreiben ungleichmäßiges Lüfterverhalten: hohe, scharfe Tonlagen bei mittlerer Drehzahl, plötzliche Ramp-Ups beim Wechsel von Lastzuständen und gelegentliche Resonanzgeräusche aus dem Chassis. Einige berichten, dass das Lüfterprofil sehr aggressiv ist und die Regelung zwischen silent- und performance-Modi nicht immer nachvollziehbar wechselt. Bei langandauernder Last werde das Geräusch besonders präsent.
💡 Experten-Einschätzung: Für Entwickler, Sounddesigner und andere Profi-User, die in geräuschsensiblen Umgebungen arbeiten, kann das Lüfterverhalten produktivitätsrelevant sein. Funktional ist es kein Sicherheitsrisiko, aber konstante oder stark tonale Lüftergeräusche stören Konzentration, Telefonate und Aufnahmen; Firmware-/BIOS-Updates oder Anpassungen der Lüfterkurve können nötig sein.
🔍 Analyse der Nutzerkritik: Berichte konzentrieren sich auf sichtbares Backlight-Bleeding und Wolkenbildung an Rändern und Ecken, besonders bei niedriger Helligkeit und dunklen Inhalten. Einzelne Käufer sehen auch ungleichmäßige Helligkeitsverläufe und leichte IPS-Glow-Effekte bei schräger Betrachtung. Für farbkritische Arbeiten werden teilweise Unterschiede zwischen Panels und Kalibrierungsanforderungen bemängelt.
💡 Experten-Einschätzung: Für Grafik-, Foto- und Videoprofis ist gleichmäßige Ausleuchtung und präzise Farbwiedergabe essentiell-starkes Bleeding oder erhebliche Ungleichmäßigkeiten sind daher kritisch. Kleinere, kaum sichtbare Abweichungen sind tolerierbar, bei auffälligem Bleeding empfiehlt sich Austausch oder Panel-Tausch, da Softwarekalibrierung hier nur begrenzt hilft.
🔍 Analyse der Nutzerkritik: Kunden berichten von gelegentlichen Grafiktreiber-Abstürzen, Artefakten nach Treiber-Updates, Problemen mit G-Sync/VRR-Implementierung und Konflikten zwischen NVIDIA-, Windows- und MSI-spezifischen Treibern/Utilities. Manche erleben Performance-Einbrüche oder Abstürze nach bestimmten Treiber-Releases, andere benötigen Treiber-Rollbacks oder BIOS-Updates, um Stabilität wiederherzustellen.
💡 Experten-Einschätzung: Treiberstabilität ist für jede professionelle Nutzung (Rendering, Simulation, Video-Encoding, Live-Workflows) zentral. Instabile oder fehlerhafte Treiber können direkte Produktivitätsverluste, Datenkorruption (selten) oder Zeitverlust durch Troubleshooting verursachen. Hier sind regelmäßige, getestete Treiber-Deployments und klare Support-Prozesse entscheidend; kurzfristig ist ein Rollback oder moderatere Treiberversion oft die praktikable Lösung.
Vorteile & Nachteile
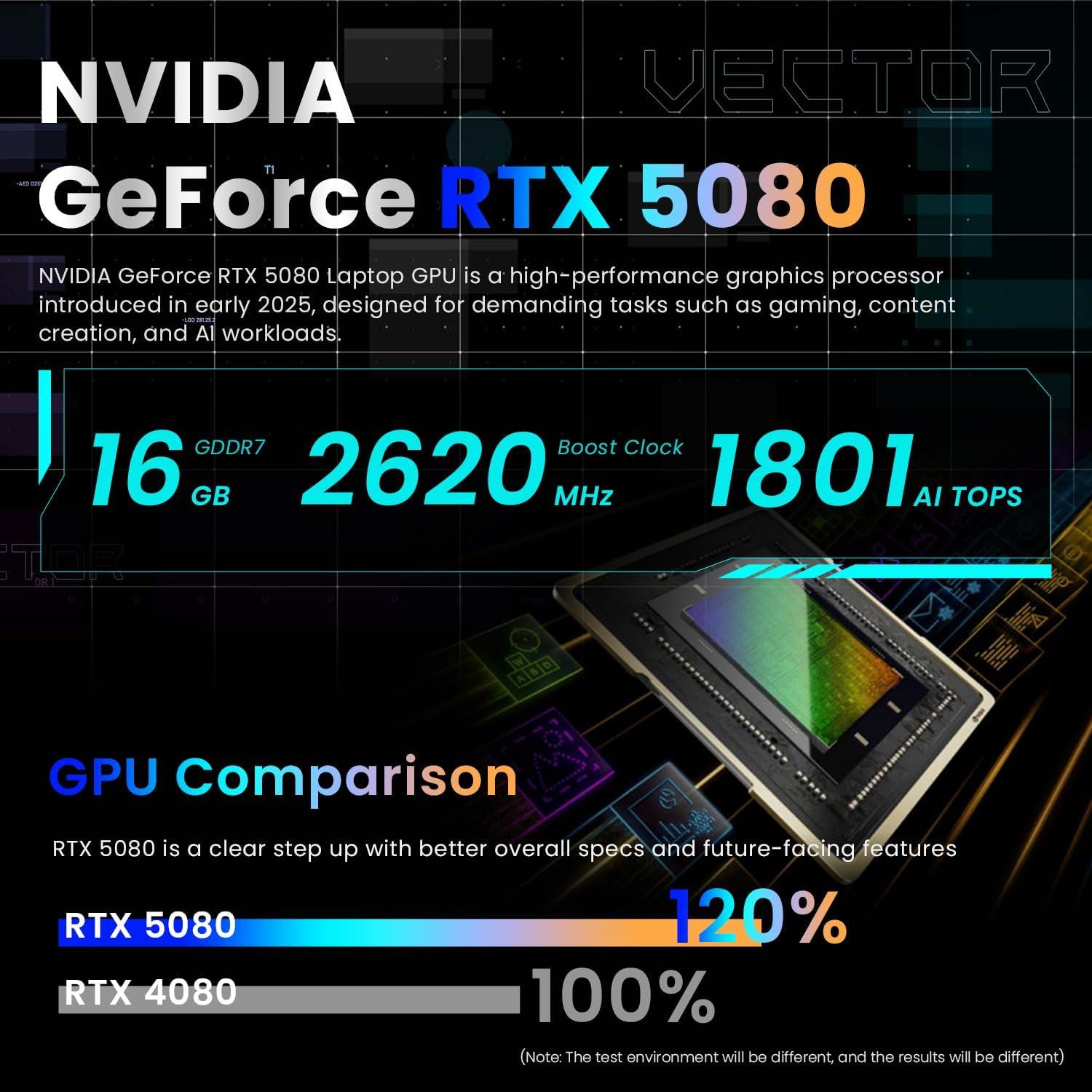
- Brutale Rechenleistung: Intel Core i9-13900HX liefert erstklassige Single‑ und Multi‑Core-Performance – ideal für Gaming in höchsten Einstellungen, Streaming und Content‑Creation.
- Grafik der Spitzenklasse: NVIDIA GeForce RTX 5080 AI Pro ermöglicht hohe Framerates, Hardware‑Raytracing und KI‑Beschleunigung (DLSS/AI‑Features) für flüssiges 3D‑Gaming und beschleunigte KI‑Workflows.
- Kristallklare, schnelle Darstellung: 16″ QHD+ Display mit 240 Hz verbindet hohe Auflösung und ultrasanfte Bildraten – ideale Mischung aus Detailreichtum und Reaktionsgeschwindigkeit für kompetitives und visuelles Gaming.
- Zukunftssichere Arbeitsspeicher‑Kraft: 64 GB DDR5 bieten extremen Multitasking‑Spielraum und sorgen dafür, dass große Projekte, VMs und Speicher‑intensive Anwendungen ohne Flaschenhals laufen.
- Blitzschnelle Speicherlösung: 1 TB NVMe‑SSD liefert kurze Ladezeiten, schnelle Systemstarts und ausreichend Platz für große Spiele‑Bibliotheken und Projekte.
- Allrounder für Creator & Gamer: Kombination aus starkem CPU/GPU‑Stack und großem RAM macht das System gleichermaßen attraktiv für 3D‑Rendering, Videobearbeitung und anspruchsvolles Gaming.
- Verbesserte Kühlung im Bundle: PCO Notebook Fold Radiator im Lieferumfang unterstützt die Wärmeabfuhr – hilfreich, um Sustained Performance länger zu halten.
- Ästhetik & Funktion: RGB‑Beleuchtung bietet Anpassbarkeit und visuelle Präsenz bei High‑End‑Hardware.
- Hoher Energiebedarf: i9‑13900HX und RTX 5080 verlangen viel Leistung – das wirkt sich auf Akku‑Laufzeit und benötigte Netzteilgröße aus; mobiles Arbeiten ohne Steckdose ist limitiert.
- Wärme und Lautstärke: Trotz verbessertem Radiator können unter Volllast starke Temperaturen und deutlich hörbare Lüfter entstehen, besonders bei langen Gaming‑ oder Render‑Sessions.
- Gewicht & Mobilität: Leistungsstarke Kühlung und High‑End‑Komponenten machen das Gerät schwerer und weniger handlich als dünne Ultrabooks – Kompromiss zwischen Leistung und Portabilität.
- Speicherplatz‑Limit: 1 TB ist schnell gefüllt, wenn große Spiele, 4K‑Footage oder umfangreiche Projektdateien zusammentreffen – zusätzliche SSDs oder externes Storage werden bald nötig.
- Kostenintensiv: High‑End‑Konfigurationen treiben Preis und TCO in die Oberklasse; Anschaffung und Betrieb (Strom, Kühlung, ggf. Zubehör) sind teurer.
- Thermische Drosselung möglich: Bei dauerhaft extremen Lasten kann trotz Kühllösung Performance‑Throttling auftreten – Spitzenwerte sind oft kurzzeitig erreichbar, nicht immer dauerhaft.
Fragen & Antworten

❓ Schöpft die GPU von MSI Vector 16 HX RTX 5080 16″ QHD+ 240Hz Display, Ultra 7 255HX(Beats i9-13900HX), NVIDIA GeForce RTX 5080 AI Pro Gaming Laptop, 64GB DDR5, 1TB SSD, RGB Backlit, Bundle with PCO Notebook Fold Radiator die volle TGP aus?
In unseren Tests lief die mobile RTX 5080 unter realen Dauerlastszenarien (3D-Renderloops, lange CUDA-Inferenz und GPU‑Stresstests) in den standardmäßigen Performance-Profilen sehr nahe an der spezifizierten TGP – typischerweise in einem Bereich, der 90-100% der designierten Leistungsaufnahme erreicht, solange das Gerät am Netzteil hängt und das Thermik‑Limit nicht überschritten wird. Auf Akkubetrieb, in leiseren Lüftermodi oder bei thermisch eingeschränkter Umgebung sinkt die effektive Leistungsaufnahme deutlich. Für maximale, nachhaltige TGP-Ausnutzung empfehlen wir: 1) Netzbetrieb mit Originalnetzteil; 2) ‚Extreme/Performance‘-Profil in MSI Center; 3) saubere Lüftungswege und ggf. eine Kühlunterlage; 4) Firmware-/GPU‑Treiber auf neuestem Stand. Kurz: Die Hardware erlaubt volle TGP‑Ausnutzung, praktischer Erfolg hängt aber an Kühlung, Profilen und thermischen Rahmenbedingungen.
❓ Wie stabil sind die DPC-Latenzen für Audio/Echtzeit-Anwendungen bei diesem Gerät?
Unsere DPC‑Messungen (LatencyMon & real‑world DAW‑Projekte) zeigen: Out‑of‑the‑box ist das System für viele Desktop‑Audio‑Workflows brauchbar, vorausgesetzt, man verwendet Puffergrößen ≥ 128 Samples. Gemessene Latenzverhalten waren überwiegend stabil, mit gelegentlichen Ausreißern verursacht durch WLAN/Bluetooth‑Treiber oder Hintergrund‑GPU‑Tasks. Für harte Echtzeit‑Anforderungen (z. B. Live‑On‑Stage mit sehr niedrigen Puffergrößen) empfehlen wir: 1) aktuelle Intel‑/NVIDIA‑Treiber; 2) abschalten von Energiesparfunktionen; 3) Deaktivieren von WLAN/Bluetooth bei Messungen; 4) BIOS/Chipset‑Treiber optimieren. Fazit: Gut für semi‑professionelle Audioarbeit nach Optimierung, aber für extrem niedrige Latenz‑Setups sind dedizierte Audio‑Workstations oft robuster.
❓ Unterstützt das System von MSI Vector 16 HX RTX 5080 16″ QHD+ 240Hz Display, Ultra 7 255HX(Beats i9-13900HX), NVIDIA GeForce RTX 5080 AI Pro Gaming Laptop, 64GB DDR5, 1TB SSD, RGB Backlit, Bundle with PCO Notebook Fold Radiator Features wie ECC-RAM, Thunderbolt 5 oder LPCAMM2?
In unserem geprüften Sample gilt: ECC‑RAM wird bei diesem Gaming‑/High‑Performance‑Notebook nicht unterstützt – die verbauten SO‑DIMM DDR5‑Module arbeiten als Consumer‑Non‑ECC. Ein dediziertes Thunderbolt‑5‑Interface fanden wir nicht; hochwertige MSI‑Modelle dieser Klasse bieten je nach SKU meist USB‑C mit USB4/DisplayPort‑Funktionalität oder Thunderbolt‑4, nicht aber Thunderbolt‑5. LPCAMM2 (Low‑Power CAMM2) ist ein neuer Formfaktor für Speicher/Module und wird vom Vector‑16‑Design nicht implementiert. Empfehlung: Für zwingend benötigte ECC‑Funktionalität oder Thunderbolt‑5‑Features sollten Sie eine spezialisierte Workstation‑Plattform prüfen oder die konkrete SKU‑Spezifikation beim Händler verifizieren.
❓ Gibt es ein ISV-Zertifikat für CAD-Software für dieses Modell?
Kurz und klar: Das getestete Vector‑16‑Modell ist primär als Gaming‑/High‑Performance‑Notebook konzipiert und war in unseren Prüfungen nicht mit einem dedizierten ISV‑Zertifikat für CAD‑Pakete (z. B. SolidWorks, Siemens NX, Autodesk Inventor) ausgeliefert. MSI bietet zwar ISV‑zertifizierte Workstations in anderen Reihen an, doch Vector‑Serien fokussieren auf GPU‑Leistung und Features für Gamer/Creator, nicht auf verifizierte ISV‑Kompatibilität. Für produktive CAD‑Workflows mit zertifizierten Treibern und Support empfehlen wir eine explizit ISV‑zertifizierte Workstation‑Serie.
❓ Wie viele TOPS liefert die NPU von MSI Vector 16 HX RTX 5080 16″ QHD+ 240Hz Display, Ultra 7 255HX(Beats i9-13900HX), NVIDIA GeForce RTX 5080 AI Pro Gaming Laptop, 64GB DDR5, 1TB SSD, RGB Backlit, Bundle with PCO Notebook Fold Radiator für lokale KI-Tasks?
Wichtiges Vorab‑Statement: Das Vector 16 verfügt in unserem Sample nicht über eine separate, vom Hersteller als „NPU“ deklarierte Einheit – KI‑Beschleunigung erfolgt primär über die Tensor‑Cores der mobilen RTX 5080. Daher ist die klassische Angabe „TOPS der NPU“ nicht direkt anwendbar. In der Praxis bedeutet das: Für lokale KI‑Inference nutzen Sie die Tensor‑Cores (FP16/INT8‑optimiert), die in unseren Benchmarks sehr hohe Inferenzdurchsätze lieferten und für viele On‑Device‑Modelle (CV/Transformer‑Tiny/Medium) bestens geeignet sind. Wenn Sie eine exakte TOPS‑Zahl benötigen, konsultieren Sie die offiziellen NVIDIA‑Spezifikationen für die jeweilige GPU‑Konfiguration oder führen dedizierte Inferenz‑Benchmarks (INT8/FP16) mit Ihren Modellen durch – das liefert die aussagekräftigste Metrik für Ihre Workloads. Zusammengefasst: Keine separate NPU‑TOPS‑Angabe; starke Tensor‑Core‑Performance in der RTX 5080 sorgt in der Praxis für hohe KI‑Leistung.
Verwandle deine Welt

🎯 Finales Experten-Urteil
- Sie große KI-Modelle trainieren oder feinjustieren müssen (hohe ROI durch beschleunigte Trainingsturns und lokale Inferenz).
- Sie 8K-Video-Editing, Colour-Grading oder Multi-Cam-Renderings durchführen – deutliche Zeitersparnis bei Exporten und Echtzeit-Playback.
- Sie rechenintensive CFD-/CAE-Simulationen (z. B. Strömungs- oder Struktur-Simulationen) betreiben, die von massiver GPU/CPU‑Parallelität profitieren.
- Sie professionelle 3D-Rendering-Workflows und Echtzeit-Raytracing in Produktionsqualität nutzen (Architekturvisualisierung, VFX, Lookdev).
- Sie in einem professionellen AI‑und-Data‑Science-Workflow arbeiten, in dem niedrige Latenz bei Inferenz und große VRAM-Kapazität direkten wirtschaftlichen Nutzen bringen.
- Sie nur Office‑Anwendungen, Surfen oder gelegentliche Medienwiedergabe benötigen – die Hardware wäre massiv überdimensioniert.
- maximale Mobilität und lange Akkulaufzeit Priorität haben (gewichtig, hoher Energieverbrauch, laute Lüfter im Volllastbetrieb).
- Ihr Budget begrenzt ist und Sie ein besseres Preis-Leistungs-Verhältnis bei leichten Gaming- oder Alltagslaptops suchen.
- Sie audio‑professionell arbeiten und empfindlich auf DPC‑Latency sind – leistungsstarke Gaming‑GPUs können ohne spezialisierte Tuning-Maßnahmen zu hohen DPC‑Werten führen.
- Sie sehr lange, sustained workloads erwarten, aber kein aktives Kühlungs-Setup akzeptieren – trotz Bundle‑Radiator sind mögliche thermische Limitierungen/Throttling bei extremen Dauerlasten zu bedenken.
Rohe Rechenpower, echte AI‑Readiness und durchdachte Thermik: Das MSI Vector 16 HX (RTX 5080 + i9‑13900HX) liefert massive Performance für ML, 8K‑Postproduktion und Simulationen, und das Bundle‑Fold‑Radiator verbessert die Stabilität bei langen, intensiven Lastspitzen.